NVIDIA is the other big player in the GPU field with regard to HPC. Its latest product is the Tesla C2050/C2070, also known as the "Fermi" card. A simplified block diagram is shown in Figure 22.
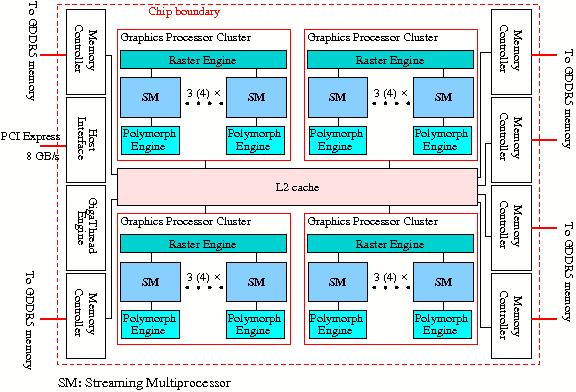
Figure 22: Simplified block diagram of the NVIDIA Tesla C2050/2070 GPU.
The GigaThread Engine is able to schedule different tasks in the Streaming
Multiprocessors (SMs) in parallel. This greatly improves the occupation rate of
the SMs and thus the throughput. As shown in Figure
Figure 22 3 (or 4) SMs per Graphics Processor Cluster (GPC)
are present. At the moment not more than a total of 14 SMs are available,
although 16 were planned. When the 40 nm production process has improved
sufficiently the number of SMs may increase from to the originally planned 16. A
newly introduced feature is the L2 cache that is shared by all SMs. Also there
is DMA support to get data from the host's memory without having to interfere
with the host CPU. The GPU memory is GDDR5 that is connected to the card via 6
64-bit wide memory interfaces for a bandwidth of about 150 GB/s.
Each SM in turn harbours 32 cores that used to be named Streaming Processors
(SPs) but now are called CUDA cores by NVIDIA. A diagram of an SM with some
internals is given in Figure Figure 23.
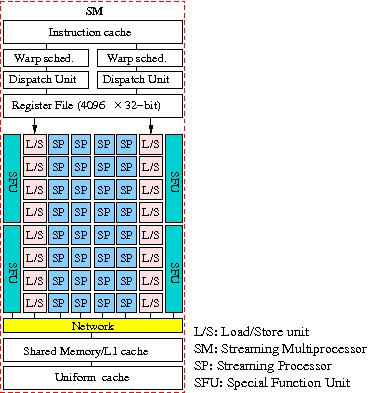
Figure 23: Diagram of a Streaming Processor of the NVIDIA Tesla C2050/C2070.
Via the instruction cache 2 Warp schedulers (a warp is a bundle 32 threads) the program threads are pushed onto the SPs. In addition each SM has 4 Special Function Units that take care of the evaluation of functions that are more complicated than profitably can be computed by the simple floating-point units in the SPs.
Lastly, we list some properties of the Tesla C2050/70 in the table below.
| Number of processors | 448 |
| Memory (GDDR5), C2050 | 3 GB |
| Memory (GDDR5), C2070 | 6 GB |
| Internal bandwidth | ≤ 153 GB/s |
| Clock Cycle | 1.15 GHz |
| Peak Perfomance (32-bit) | 1.03 Tflop/s |
| Peak Perfomance (64-bit) | 515 Gflop/s |
| Power requirement (peak) | ≤ 238 W |
| Interconnect (PCIe Gen2) | 8×, 4 GB/s;16×, 8 GB/s |
| Error correction | Yes |
| Floating-point support | Full (32/64-bit) |
From these specifications can be derived that 2 32-bit floating-point results
per core per cycle can be delivered. The peak power requirement given will
probably be an appropriate measure for HPC workloads. A large proportion of the
work being done will be from the BLAS library that is provided by NVIDIA, more
specifically, the dense matrix-matrix multiplication in it. This operation
occupies any computational core to the full and will therefore consume close to
the maximum of the power. As can be seen from the table the only difference
between the C2050 and the C2070 is the amount of memory: the C2050 features 3 MB
of GDDR5 memory while the C2070 has double that amount.
Like ATI, NVIDIA provides an SDK comprised of a compiler named CUDA, libraries
that include BLAS and FFT routines, and a runtime system that accomodates both
Linux (RedHat and SuSE) and Winodws. CUDA is a C/C++-like language with
extensions and primitives that cause operations to be executed on the card
instead of on the CPU core that initiates the operations. Transport to and from
the card is done via library routines and many threads can be initiated and
placed in appropriate positions in the card memory so as not to cause memory
congestion on the card. This means that for good performance one needs knowledge
of the memory structure on the card to exploit it accordingly. This is not
unique to the C2050 GPU, it pertains to the ATI Firestream GPU and other
accelerators as well.
NVIDIA also supports OpenCL, though CUDA is at present much more popular among
developers. For Windows users the NVIDIA Parallel Nsight for Visual Studio is
available that should ease the optimisation of the program parts run on the
cards.