Until recently Myrinet was the market leader in fast cluster networks and it is still one of the largest. The Myricom company which sells Myrinet started in 1994 with its first Myrinet implementation, [24], as an alternative for Ethernet to connect the nodes in a cluster. Apart from the higher bandwidth, around 100 MB/s at that time, the main advantage was that it entirely operated in user space, thus avoiding Operating System interference and the delays that come with it. This meant that the latency for small messages was around 10–15 µs. Latency and bandwidth compared nicely with the proprietary networks of integrated parallel systems of Convex, IBM, and SGI at the time. Although such a network came at a non-negligible cost, in many cases it proved a valuable alternative to either an Ethernet connected system or an even costlier integrated parallel system.
Since then hardware upgrades and software improvements have made Myrinet the network of choice for many cluster builders and until a few years ago there was hardly an alternative when a fast, low-latency network was required.
Like Infiniband, Myrinet uses cut-through routing for an efficient utilisation
of the network. Also RDMA is used to write to/read from the remote memory of
other host adaptor cards, called Lanai cards. These cards interface with the
PCI-X bus of the host they are attached to. The latest Myrinet implementation
only uses fibers as signal carriers. This gives a high flexibility in the
connection and much headroom in the speed of signals but the fiber cables and
connectors are rather delicate which can lead to damage when cluster nodes have
to be serviced.
Myrinet offers ready-made 8–256 port switches (8–128 for its newest product,
see below). The 8 and 16 port switches are full crossbars. In principle all
larger networks are build form these using a Clos network topology. An example
for a 64-port systems is shown in Figure 30
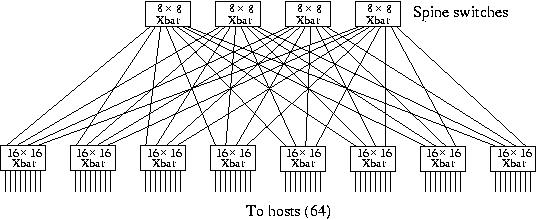
Figure 30. An 8×16 Clos network using 8 and 16 port crossbar switches to connect 64 processors.
A Clos network is another example of a logarithmic network with the maximum bisectional bandwidth of the endpoints. Note that 4 ports of the 16×16 crossbar switches are unused but other configurations need either more switches or connections or both.
Since the start of 2006 Myricom provides, like many Infiniband switch vendors, a multi-protocol switch (and adapters): The Myri-10G. Apart from Myricom's own MX protocol it also supports 10 Gigabit Ethernet which makes it easy to connect to external nodes/clusters. An ideal starting point for building grids from a variety of systems. The specifications as given by Myricom are quite good: ≅ 1.2 GB/s for the uni-directional theoretical bandwidth for both its MX protocol and about the same for the MX emulation of TCP/IP on Gigabit Ethernet. According to Myricom there is no difference in bandwidth between MX and MPI and also the latencies are claimed to be the same: just over 2 µs.