The Convey HC-1 was announced in November 2008. It is an example of the hybrid
solutions that has came up to avoid the unwieldy HDL programming of FPGAs while
still benefitting from their potential acceleration capabilities. The HC-1
comprises a familiar x86 front-end with a modified Centos Linux distribution
under the name of Convey Linux. Furthermore, there is a co-processor part that
contains 4 Xilinx V5 FPGAs that can be configured into a variety of
"personalities" that would accomodate users from different application areas.
Personalities offered are, e.g., Oil and Gas industry, Financial Analytic
market, and the Life Sciences.
In Figure 28 we give a diagram of the HC-1 co-processors's
structure.
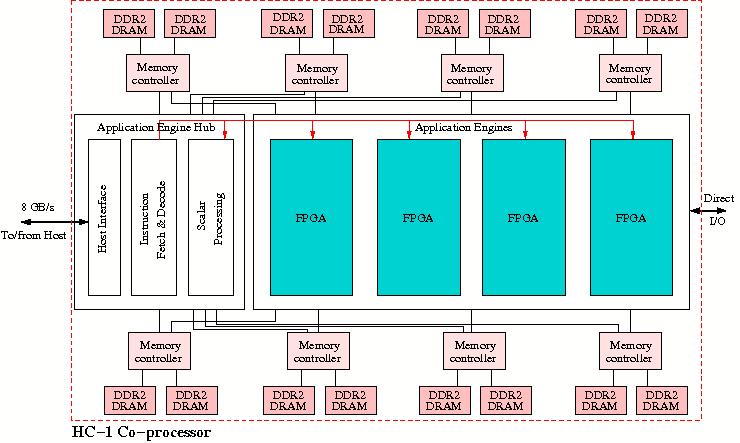
Figure 28: Block diagram of the Convey HC-1.
A personality that will be often used for scientific an technical work is the
vector personality. Thanks to the compilers provided by Convey standard code in
Fortran and C/C++ can be automatically vectorised and executed the vector units
that have been configured in the 4 FPGAs for a total of 32 function pipes.
Each of these contain a vector register file, four pipes that can execute
Floating Multiply Add instructions, pipe for Integer, Logical, Divide, and
Miscellaneous instructions and a Load/Store pipe. For other selected
personalities the compilers will generate code that is optimal for the
instruction mix generated for the appropriately configured FPGAs in the
Application Engine.
The Application Engine Hub shown in Figure 28 contains the
interface to the x86 host but also the part that maps the instructions onto the
application engine. In addition, it will perform some scalar processing that is
not readily passed on to the Application Engine.
Because the system has many different faces, it is hard to speak about
the peak performance of the system. As yet there is too little experience
with the HC-1 to compare it 1-to-1 with other systems in terms of performance.
However, it is clear that the potential speedup for many applications can be
large.