The class of DM-MIMD machines represents undoubtedly the largest fraction in the
family of high-performance computers. A generic diagram is given in Figure
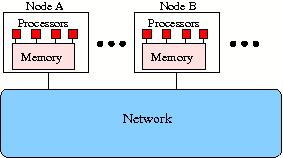
Figure 6: Generic diagram of a DM-MIMD machine.
The figure shows that within a computational node A, B, etc., a number of
processors (four in this case) draw on the same local memory and that the nodes
are connected by some network. Consequently, when a processor in node A needs
data present in node B this have to accessed through the network. Hence the
characterisation of the system as being of the distributed memory type. The vast
majority of all HPC systems today are a variation of the model shown in Figure
Alternatively, instead of message passing a Partitioned Global Address Space parallelisation model may be used with a programming language like UPC [40] or Co-Array Fortran [4]. In this case one still has to be aware where the relevant data are but no explicit sending/receiving between processors is necessary. This greatly simplifies the programming but the compilers are still either fairly immature or even in an experimental stage which does not always guarantee a great performance to say the least.
The advantages of DM-MIMD systems are clear: the bandwidth problem that haunts shared-memory systems is avoided because the bandwidth scales up automatically with the number of processors. Furthermore, the speed of the memory which is another critical issue with shared-memory systems (to get a peak performance that is comparable to that of DM-MIMD systems, the processors of the shared-memory machines should be very fast and the speed of the memory should match it) is less important for the DM-MIMD machines, because more processors can be configured without the afore mentioned bandwidth problems.
Of course, DM-MIMD systems also have their disadvantages: The communication between processors is much slower than in SM-MIMD systems, and so, the synchronisation overhead in case of communicating tasks is generally orders of magnitude higher than in shared-memory machines. Moreover, the access to data that are not in the local memory belonging to a particular processor have to be obtained from non-local memory (or memories). This is again on most systems very slow as compared to local data access. When the structure of a problem dictates a frequent exchange of data between processors and/or requires many processor synchronisations, it may well be that only a very small fraction of the theoretical peak speed can be obtained. As already mentioned, the data- and task decomposition are factors that mostly have to be dealt with explicitly, which may be far from trivial.
It will be clear from the paragraph above that also for DM-MIMD machines both the topology and the speed of the datapaths are of crucial importance for the practical usefulness of a system. Again, as in the section on SM-MIMD systems, the richness of the connection structure has to be balanced against the costs. Of the many conceivable interconnection structures only a few are popular in practice. One of these is the so-called hypercube topology as depicted in Figure 7(a).

Figure 7: Some often used networks for DM machine types.
A nice feature of the hypercube topology is that for a hypercube with 2d nodes the number of steps to be taken between any two nodes is at most d. So, the dimension of the network grows only logarithmically with the number of nodes. In addition, theoretically, it is possible to simulate any other topology on a hypercube: trees, rings, 2-D and 3-D meshes, etc. In practice, the exact topology for hypercubes does not matter too much anymore because all systems in the market today employ what is called "wormhole routing". This means that a message is send from i to node j a header message is sent from i to j, resulting in a direct connection between these nodes. As soon this connection is established, the data proper is sent through this connection without disturbing the operation of the intermediate nodes. Except for a small amount of time in setting up the connection between nodes, the communication time has become virtually independent of the distance between the nodes. Of course, when several messages in a busy network have to compete for the same paths, waiting times are incurred as in any network that does not directly connect any processor to all others and often rerouting strategies are employed to circumvent busy links if the connecting network supports it. Also the network nodes themselves have become quite powerful and, depending on the type of network hardware may send and re-rout message packages in a way that minimises contention.
Another cost-effective way to connect a large number of processors is by means of a fat tree. In principle a simple tree structure for a network is sufficient to connect all nodes in a computer system. However, in practice it turns out that near the root of the tree congestion occurs because of the concentration of messages that first have to traverse the higher levels in the tree structure before they can descend again to their target nodes. The fat tree amends this shortcoming by providing more bandwidth (mostly in the form of multiple connections) in the higher levels of the tree. One speaks of a N-ary fat tree when the levels towards the roots are N times the number of connections in the level below it. An example of a quarterny fat tree with a bandwidth in the highest level that is four times that of the lower levels is shown in Figure 7(b).
A number of massively parallel DM-MIMD systems favour a 2-D or 3-D mesh (torus) structure. The rationale for this seems to be that most large-scale physical simulations can be mapped efficiently on this topology and that a richer interconnection structure hardly pays off. However, some systems maintain (an) additional network(s) besides the mesh to handle certain bottlenecks in data distribution and retrieval [17]. Also in the IBM BlueGene/P system this philosophy has been followed.
A large fraction of systems in the DM-MIMD class employ crossbars. For relatively small amounts of processors (in the order of 64) this may be a direct or 1-stage crossbar, while to connect larger numbers of nodes multi-stage crossbars are used, i.e., the connections of a crossbar at level 1 connect to a crossbar at level 2, etc., instead of directly to nodes at more remote distances in the topology. In this way it is possible to connect many thousands of nodes through only a few switching stages. In addition to the hypercube structure, other logarithmic complexity networks like Butterfly-, Ω-, or shuffle-exchange networks are often employed in such systems.
As with SM-MIMD machines, a node may in principle consist of any type of processor (scalar or vector) for computation or transaction processing together with local memory (with or without cache) and, in almost all cases, a separate communication processor with links to connect the node to its neighbours. Nowadays, the node processors are mostly off-the-shelf RISC or x86 processors sometimes enhanced by vector processors. A problem that is peculiar to these DM-MIMD systems is the mismatch of communication vs. computation speed that may occur when the node processors are upgraded, without also speeding up the intercommunication. In many cases this may result in turning computational-bound problems into communication-bound problems and one sees much research activities to find communication avoiding algorithms that try to minimise the communication even at the expense of recalculating intermediate results.