An FPGA (Field Programmable Gate Array) is an array of logic gates that can be
hardware-programmed to fulfill user-specified tasks. In this way one can devise
special purpose functional units that may be very efficient for this limited
task. Moreover, it is possible to configure a multiple of these units on an FPGA
that work in parallel. So, potentially, FPGAs may be good candidates for the
acceleration of certain applications. Because of their versatility it is
difficult to specify where they will be most useful. In general, though, they
are not used for heavy 64-bit precision floating-point arithmetic. Excellent
results have been reported in searching, pattern matching, signal- and
image-processing, encryption, etc. The clock cycle of FPGAs is low as compared
to that of present CPUs: 100--550 MHz which means that they are very power
effective. All vendors provide runtime environments and drivers that work with
Linux as well as Windows.
Tradionally, FPGAs are configured by describing the configuration by means of a
hardware description language (HDL), like VHDL or Verilog. This is very
cumbersome for the average programmer as one not only has to explicitely define
such details as the placement of the configured devices but also the width of
the operands to be be operated on, etc. This problem has been recognised by
FPGA-based vendors and a large variety of programming tools and SDKs have come
into existence. Unfortunately, they differ enormously in approach and the
resulting programs are far from compatible. Also for FPGA-based accelerators,
like for GPUs, there is an initiative to develop a unified API that will assure
compatibility between platforms. The non-profit OpenFPGA consortium is heading
this effort and at the time of writing this report a 0.4 version of the API is
out for comment by vendors and users. Meanwhile one has to make do with the many
dialects and APIs that are around in this area.
The two big players on the FPGA market are Altera and Xilinx. However, in the
accelerator business one seldom will find these names mentioned, because the
FPGAs they produce are packaged in a form that makes them usable for accelerator
purposes.
It is not possible to fully discuss all vendors that offer FPGA-based products.
One reason is that there is a very large variety of products ranging form
complete systems to small appliances housing one FPGA and the appropriate I/O
logic to communicate with the outside world. To complicate matters further, the
FPGAs themselves come in many variants, e.g., with I/O channels, memory blocks,
multipliers, or DSPs already configured (or even fixed) and one can choose for
FPGAs that have for instance a PowerPC405 embedded. Therefore we present the
FPGA accelerators here only in the most global way and necessarily
incomplete.
We will now discuss some of the accelerator products on the market and in what
way they are made useful.
DRC
DRC sells various products based on the Xilinx Virtex-5 FPGA. These products range from a co-processor, called the Accelium 2000, that can be directly connected to AMD's HyperTransport, via 2U and 4U rack-mounted servers to a tower workstation in which up to 3 co-processors can be accomodated. There is an integrating software environment that contains the DRC API and driver on the CPU side (in practice an Opteron processor) and DRC's hardware OS on the co-processor side. DRC modules with the Xilinx Virtex-4 LX200 are employed in the Cray XR1 blades that fit into the Cray XT5 infrastructure, thus making it a hybrid computer.Software development for the DRC processors can, e.g., be done using Handel-C or Mitrion-C that can generate loadable code for Altera as well as Xilinx FPGAs. On one hand there are, however, restrictions with regard to standard C, on the other hand there are extensions, for instance to describe operand width. It therefore is highly chip-specific whether the code will run satisfactorily (or sometimes at all). Good Developments Kits, like that of Mitrion for instance, will notify the user, however, when he/she wants the impossible.
Nallatech
Nallatech offers an enhancement for IBM BladeCenter hardware, both as complete cards and as an expansion card. The H102 cards contain 2 Xilinx Virtex-4 LX-100 FPGAs. In addition a general accelerator card, H101, with 1 Virtex-4 is available that can be connected via a PCI-X slot. Floating-point arithmetic is pre-configured. For the H102 cards the peak speed is 12.8 Gflop/s in 64-bit presicion and 40 Gflop/s in 32-bit precision while it is half this speed for the PCI-X-based H101 card.Nallatech has its own API, FUSE, to manage the configuration, control, and communication with the rest of the system. With it comes Dimetalk that for some functions transform restricted type of C code, DIME-C, into VHDL and can generate the communication network between the various algorithm blocks, memory blocks I/O interfaces.
Pico
Pico markets its so-called E-12 cards in two varieties: the E-12 LX25 contains a Xilinx Virtex-4 LX25 FPGA while the E-12 FX12 has a similar FPGA but with a 450 MHz PowerPC 405 core embedded. The latter can be convenient when one also wants operating systems tasks to be done of which the results directly impact the operation on the FPGA. This is, however, generally not the case in HPC applications. Furthermore, a tower model workstation with up to 15 E-12 LX25 cards is available as well as a 4U rack-mounted model with room for 77 of the larger Virtex-4 LX50 cards. Performance measures given are typical for FPGA systems: 32×109 18×18 fixed-point multiplies/s (a standard in image processing), 400 million DES encryption keys/s, etc.As Pico exclusively uses Xilinx Virtex FPGAs it is not surprising that it offers the full Xilinx standard toolset, EDI, EDK, and Platform EDK. The capabilities of these tools remains, however, unclear as the information content of the online product description is minimal.
SGI RASC
Since a few years SGI has its RASC RC100 blade on the market. It contains 2 Xilinx Virtex-4 LX200 FPGAs as well as NumaLink connection ports to fit it into SGI's Altix 4700 and 450 systems as accelerator boards. It can be regarded as an expression of SGI's interest in hybrid computing systems. Because the product is there already for some years there is a reasonable software base in the form of a library, RASClib, and various developing platforms are supported, including Handel-C, Impulse Codeveloper/Impulse-C, and Mitrion-C.
SRC
SRC is the only company that sells a full stand-alone FPGA accelerated system, named the SRC-7. Besides that the so-called SRC-7 MAP station is sold, the MAP being the processing unit that contains 2 Altera Stratix II FPGAs. Furthermore, SRC has the IMAP card as a product that can be plugged in a PCIe slot of any PC.SRC has gone to great length to ban the term FPGA from its documentation. Instead it talks about implicit vs. explicit computing. In SRC terms implicit computing is performed on standard CPUs while explicit computing is done on its (reconfigurable) MAP processor. The SRC-7 systems have been designed with the integration of both types of processors in mind and in this sense it is a hybrid architecture also because shared extended memory can be put into the system that is equally accessible by both the CPUs and the MAP processors. We show a sketch of the machine structure in Figure 25.
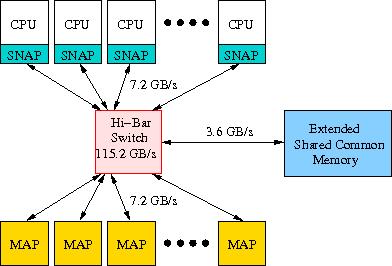
Figure 25: Approximate machine structure of the SRC-7.
It shows that CPUs and MAP processors are connected by a 16×16 so-called Hi-Bar crossbar switch with a link speed of 7.2 GB/s. The maximum aggregate bandwidth in the switch 115.2 GB/s, enough to route all 16 independent data streams. The CPUs must be of the x86 or x86_64 type. So, both Intel and AMD processors are possible. As can be seen in the Figure the connection to the CPUs is made through SRCs proprietary SNAP interface. This accommodates the 7.2 GB/s bandwidth but isolates it from the vendor-specific connection to memory. Instead of configuring a MAP processor, also common extended memory can be configured. This allows for shared-memory parallelism in the system across CPUs and MAP processors.
The MAP station is a shrunk version of the SRC-7: it contains a x86(_64) CPU, a MAP processor, and a 4×4 Hi-Bar crossbar that allows Common Extended memory to be configured.
SRC is the only accelerator vendor that supports direct support for Fortran through its development environment Carte. In addition, of course also C/C++ is available. The parallelisation and acceleration are largely done by putting comment directives in Fortran code and pragmas in C/C++ code. Also, explicit memory management and prefetching can be done in this way. The directives/pragmas cause a bitstream to by loaded onto the FPGAs in one or more MAP processors that configures them and executes the target code. Furthermore, there is an extensive library of functions, a debugger and a performance analyzer. When one wants to employ specific non-standard funtionality, e.g., computing with arithmetic of non-standard length, one can create a so-called Application Specific Funtional Unit. In fact, one then configures one or more of the FPGAs directly and one has to fall back on VHDL or Verilog for this configuration.